

The LLM-Powered SIEM
Uniting Large Language Models and Wazuh


Intro
A few weeks ago, I came across an insightful comment in a forum:
"I'm not sure how to feel about providing critical information about my infrastructure with potential vulnerabilities to a third-party app like ChatGPT."
This comment highlights a broader challenge in the realm of cybersecurity: how can we protect our sensitive data from external entities, while still taking advantage of the latest technologies?
One promising solution is to converge Large Language Models (LLMs) with SIEM frameworks. LLMs are powerful AI tools that can be used to process and analyze large amounts of text data. SIEMs, on the other hand, are designed to collect, store, and correlate security events from across an organization's network. By combining these two technologies, we can create a more comprehensive and sophisticated cybersecurity solution that is both self-reliant and secure.
The convergence of LLMs with a robust SIEM framework like WAZUH offers a promising pathway forward, void of reliance on external entities. As these technologies continue to develop, we can expect to see even more innovative and effective ways to use them to protect our organizations from cyber threats.
What is the GPT4ALL project?
GPT4ALL is an open-source ecosystem of Large Language Models that can be trained and deployed on consumer-grade CPUs. The goal of GPT4ALL is to make powerful LLMs accessible to everyone, regardless of their technical expertise or financial resources.
GPT4ALL models are trained on a massive dataset of text and code, including code, stories, and dialogue. This dataset is carefully curated to ensure that the models can generate high-quality text that is both informative and creative.
The models can be used for a variety of tasks, including:
Text generation
Question answering
Code generation
Creative writing
The project is still under development, but it has the potential to revolutionize the way we interact with systems. By making powerful LLMs accessible to everyone, GPT4ALL can help us to create more intelligent and user-friendly security tools.
Here are some of the key features:
Open source: GPT4ALL is an open-source project, which means that anyone can contribute to its development. This makes it possible for the community to collectively improve the quality of the models and make them more accessible to everyone.
Scalable: Models can be trained on a variety of hardware platforms, from small personal computers to large cloud servers.
Efficient: The models are designed to be efficient, so they can be run on consumer-grade CPUs. You can deploy models on a wide range of devices, from laptops to smartphones.
Secure: All GPT4ALL models are trained on a dataset that has been carefully curated to remove harmful or biased content.
The GPT4ALL project is a major step forward in the development of LLMs.
Getting Started with GPT4All in Python
As you've probably guessed, there's a Python package called gpt4all that offers bindings to the GPT4All C-API. This enables you to utilize GPT4All directly from your Python code.
To employ gpt4all, you'll need to install the package first. This can be achieved using the following command:
pip install gpt4all
Once you have installed the package, you can start using it. The following code shows how to generate text using the GPT4All library:
import gpt4all
# Initialize a GPT4All model using a pre-trained model file.
model = gpt4all.GPT4All("/Users/whatdoeskmean/GPT4ALL/ggml-model-gpt4all-falcon-q4_0.bin")
prompt = "What is a Blue Teamer?"
# Generate text using the GPT4All model based on the provided prompt.
generated_text = model.generate(prompt)
# Show results
print(generated_text)
The final result should look something like this:
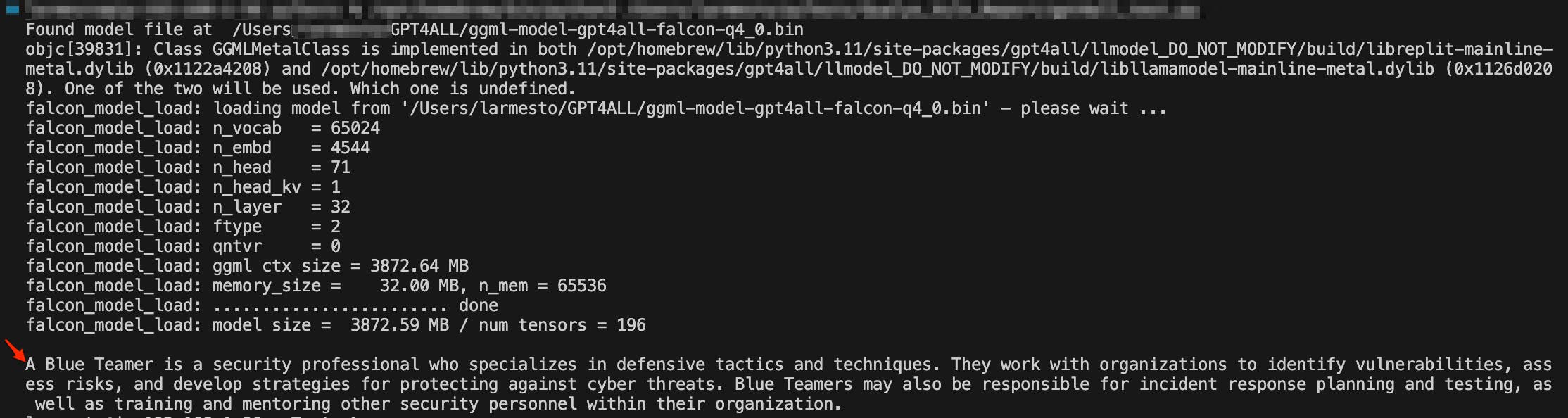
Key Reminder: LLMs are very computationally expensive models and require a lot of processing power to run. Advanced Vector Extensions (AVX) are a set of instructions that can be used to speed up certain types of mathematical operations. Having a CPU that supports AVX can significantly improve performance. LLMs also require a lot of memory.
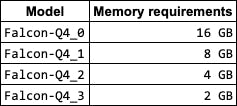
The amount of memory you need to run the GPT4all model depends on the size of the model and the number of concurrent requests you expect to receive. The Falcon-Q4_0 model, which is the largest available model (and the one I'm currently using), requires a minimum of 16 GB of memory. If you expect to receive a large number of concurrent requests, you may need to increase the amount of memory to 32 GB or more.
Here is a table of the minimum memory requirements for the different GPT4All models:
If you don't have a CPU that supports AVX or enough RAM, you may experience performance issues when running LLMs or not be able to instantiate them at all (The models may take longer to load and run, and they may not perform as well as they would on a system with better hardware). Trust me, I learned the hard way...
In my case, I have a Proxmox deployment with multiple virtualization nodes. Proxmox Virtual Environment (Proxmox VE) is an open-source virtualization management platform that combines two virtualization solutions: KVM (Kernel-based Virtual Machine) for virtual machines and LXC (Linux Containers) for lightweight container-based virtualization.
CPU(s): 4 x Intel(R) Core(TM) i5-7200U CPU @ 2.50GHz (1 Socket)
Kernel-Version: Linux 5.15.30-2-pve #1 SMP PVE 5.15.30-3
PVE Manager Version: pve-manager/7.2-3/c743d6c1
Within this deployment, I've set up a variety of virtual machines to serve different purposes.
One of these VMs is currently running a Flask web server, leveraging the instantiated GPT4All model. This server provides the API endpoint that allows users to generate text based on prompts they send to the server. The GPT4All model powers this capability, making it possible to create coherent and contextually relevant text responses. Another VM hosts my Wazuh Manager.
Example of CPU and Memory Usage within Flask server:

Developing an API endpoint for our Model.
I decided to use Flask because of its lightweight yet powerful framework that perfectly suits the requirements of our project.
Its simplicity and ease of integration allow for efficient development and deployment of our API endpoint. Additionally, Flask's extensive documentation and active community support ensure that we can readily find solutions to any challenges we may encounter during the implementation process.
Note: The choice of a Web framework ultimately depends on your specific needs and project goals. While Flask aligns well with our current objectives, there are various other frameworks available, each with its strengths and advantages. Ultimately, the decision rests on selecting the framework that best fits your project's unique requirements, ensuring optimal functionality and performance for your API endpoint.
When dealing with large datasets or extensive computations, parallelizing tasks can significantly speed up the process.
Joblib is a Python library that provides easy-to-use parallelism, allowing you to leverage all CPU cores.
To employ Joblib, you'll need to install the package first using the following command:
pip install joblib
This code sets up a Flask web application that serves as an interface for generating text using the GPT4All language model. Here's how you can utilize it for parallel computations:
import gpt4all
import flask
from joblib import Parallel, delayed
app = flask.Flask(__name__)
model = gpt4all.GPT4All(model_name='ggml-model-gpt4all-falcon-q4_0.bin', allow_download=False, model_path='/Users/whatdoeskmean/GPT4ALL')
@app.route("/generate", methods=["POST"])
def generate():
prompt = flask.request.json["prompt"]
# Number of parallel jobs you want to use (adjust as needed).
num_jobs = -1 # -1 will use all available CPU cores
# Function to generate text using the GPT4All model.
def gen_response_in_parallel(prompt):
return model.generate(prompt)
# Using joblib to parallelize response generation.
generated_text = Parallel(n_jobs=num_jobs)(delayed(gen_response_in_parallel)(prompt) for _ in range(num_jobs))
return {"generated_text": generated_text}
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000, debug=True)
We have deployed our very own API, fortified with the prowess of a Large Language Model. 💪
In summary, users can send POST requests with a JSON payload containing a "prompt," and the application will respond with text generated by the GPT4All model based on that prompt.
Needless to say, you should leave this code running on an instance with the requirements previously mentioned. ⏫
GPT4All integration configuration
Step 1
We need to create a rule that generates an alert when a non-private IP has attempted to log into our server. This allows us to distinguish malicious insiders and those attempting to gain access from outside the network.
Open the Wazuh manager local rules file /var/ossec/etc/rules/local_rules.xml and add the below block:
<!-- User Failed Authentication from Public IPv4 -->
<group name="local,syslog,sshd,">
<rule id="100004" level="10">
<if_sid>5760</if_sid>
<match type="pcre2">\.+</match>
<description>sshd: Authentication failed from a public IP address > $(srcip).</description>
<group>authentication_failed,pci_dss_10.2.4,pci_dss_10.2.5,</group>
</rule>
</group>
The <match></match> block of the rule specifies that we want to perform a REGEX search to "detect" an IP address within the log.
Step 2
The below Python script takes the source IP that triggered our rule and sends it to our GPT4All API endpoint to get log information insights.
#!/var/ossec/framework/python/bin/python3
# Copyright (C) 2015-2022, Wazuh Inc.
# GPT4ALL Integration template by Leonardo Carlos Armesto (@WhatDoesKmean)
import json
import sys
import time
import os
from socket import socket, AF_UNIX, SOCK_DGRAM
import configparser
# Intialize config parser
config = configparser.ConfigParser()
# Read config file
config.read('/var/ossec/integrations/gpt4all.conf')
try:
import requests
from requests.auth import HTTPBasicAuth
except Exception as e:
print("No module 'requests' found. Install: pip install requests")
sys.exit(1)
# Global vars
debug_enabled = False
pwd = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
json_alert = {}
now = time.strftime("%a %b %d %H:%M:%S %Z %Y")
# Set paths
log_file = '{0}/logs/integrations.log'.format(pwd)
socket_addr = '{0}/queue/sockets/queue'.format(pwd)
def main(args):
debug("# Starting")
# Read args
alert_file_location = args[1]
debug("# File location")
debug(alert_file_location)
# Load alert. Parse JSON object.
with open(alert_file_location) as alert_file:
json_alert = json.load(alert_file)
debug("# Processing alert")
debug(json_alert)
# Request gpt4all info
msg = request_gpt4all_info(json_alert)
# If positive match, send event to Wazuh Manager
if msg:
send_event(msg, json_alert["agent"])
def debug(msg):
if debug_enabled:
msg = "{0}: {1}\n".format(now, msg)
print(msg)
f = open(log_file,"a")
f.write(str(msg))
f.close()
def collect(data):
full_log = data['full_log']
choices = data['generated_text']
return full_log, choices
def in_database(data, full_log):
result = data['full_log']
if result == 0:
return False
return True
def query_api(full_log):
# Calling gpt4all API Endpoint
headers = {
'Content-Type': 'application/json',
}
prompt = config.get('gpt4all', 'prompt')
endpoint = config.get('gpt4all', 'endpoint')
json_data = {"prompt": prompt + " " + full_log}
response = requests.post(endpoint, headers=headers, json=json_data)
if response.status_code == 200:
full_log = {"full_log": full_log}
new_json = {}
new_json = response.json()
new_json.update(full_log)
json_response = new_json
data = json_response
return data
else:
alert_output = {}
alert_output["gpt4all"] = {}
alert_output["integration"] = "custom-gpt4all"
json_response = response.json()
debug("# Error: The gpt4all encountered an error > " + str(response.status_code))
alert_output["gpt4all"]["error"] = response.status_code
alert_output["gpt4all"]["description"] = json_response["errors"][0]["detail"]
send_event(alert_output)
exit(0)
def request_gpt4all_info(alert):
alert_output = {}
# Request info using gpt4all API
data = query_api(alert["full_log"])
# Create alert
alert_output["gpt4all"] = {}
alert_output["integration"] = "custom-gpt4all"
alert_output["gpt4all"]["found"] = 0
alert_output["gpt4all"]["source"] = {}
alert_output["gpt4all"]["source"]["alert_id"] = alert["id"]
alert_output["gpt4all"]["source"]["rule"] = alert["rule"]["id"]
alert_output["gpt4all"]["source"]["description"] = alert["rule"]["description"]
alert_output["gpt4all"]["source"]["full_log"] = alert["full_log"]
full_log = alert["full_log"]
# Check if gpt4all has any info about the full_log
if in_database(data, full_log):
alert_output["gpt4all"]["found"] = 1
# Info about the IP found in gpt4all
if alert_output["gpt4all"]["found"] == 1:
full_log, choices = collect(data)
# Populate JSON Output object with gpt4all request
alert_output["gpt4all"]["full_log"] = full_log
alert_output["gpt4all"]["choices"] = choices
debug(alert_output)
return(alert_output)
def send_event(msg, agent = None):
if not agent or agent["id"] == "000":
string = '1:gpt4all:{0}'.format(json.dumps(msg))
else:
string = '1:[{0}] ({1}) {2}->gpt4all:{3}'.format(agent["id"], agent["name"], agent["ip"] if "ip" in agent else "any", json.dumps(msg))
debug(string)
sock = socket(AF_UNIX, SOCK_DGRAM)
sock.connect(socket_addr)
sock.send(string.encode())
sock.close()
if __name__ == "__main__":
try:
# Read arguments
bad_arguments = False
if len(sys.argv) >= 4:
msg = '{0} {1} {2} {3} {4}'.format(now, sys.argv[1], sys.argv[2], sys.argv[3], sys.argv[4] if len(sys.argv) > 4 else '')
debug_enabled = (len(sys.argv) > 4 and sys.argv[4] == 'debug')
else:
msg = '{0} Wrong arguments'.format(now)
bad_arguments = True
# Logging the call
f = open(log_file, 'a')
f.write(str(msg) + '\n')
f.close()
if bad_arguments:
debug("# Exiting: Bad arguments.")
sys.exit(1)
# Main function
main(sys.argv)
except Exception as e:
debug(str(e))
raise
This script will be saved in the /var/ossec/integrations/ path of the Wazuh Manager as custom-gpt4all.py
The file execution permissions can be changed by the chmod command. Also, don't forget to use the chown command to change the file ownership as well.
In my case:chmod 750 /var/ossec/integrations/custom-gpt4all.pychown root:wazuh /var/ossec/integrations/custom-gpt4all.py
Step 3
I've also created a new ConfigParser file named gpt4all.conf in the /var/ossec/integrations/ path to handle configuration parsing and ease prompt updates.
The config object in the Python script reads the configuration file located at /var/ossec/integrations/gpt4all.conf.
[gpt4all]
endpoint = http://<YOUR_API_ENDPOINT>:5000/generate
prompt = Regarding this log message, what are the next steps to take?
The prompt and endpoint values are retrieved from the 'gpt4all' section of the configuration file. These values are used later in the Python script.
Step 4
Now it's time to update the Wazuh manager configuration file /var/ossec/etc/ossec.conf using the integration block below:
<!-- GPT4ALL Integration -->
<integration>
<name>custom-gpt4all.py</name>
<hook_url>http://<YOUR_API_ENDPOINT>:5000/generate</hook_url>
<api_key></api_key>
<level>10</level>
<rule_id>100004</rule_id>
<alert_format>json</alert_format>
</integration>
This instructs the Wazuh Manager to call the GPT4All API endpoint anytime our rule id (100004), is triggered.
Step 5
Now, we need to capture the response sent back to the Wazuh Manager so we can observe the information gathered by our GPT4All integration.
Open the Wazuh Manager local rules file at /var/ossec/etc/rules/local_rules.xml and add the block below:
<group name="local,syslog,sshd,">
<rule id="100007" level="10">
<field name="gpt4all.full_log">\.+</field>
<description>$(gpt4all.full_log) >> ↓ RECOMMENDED NEXT COURSE OF ACTION ↓</description>
<group>authentication_failed,pci_dss_10.2.4,pci_dss_10.2.5,</group>
</rule>
</group>
Lastly, restart the Wazuh Manager.

Conclusion
Can you imagine the impact of these accomplishments in an enterprise environment? What I achieved within my home lab is just merely surface-level insights, a tantalizing glimpse into the boundless potential that awaits us on a grander scale.
Imagine deploying these advanced LLM-powered techniques across the entirety of an enterprise's security infrastructure. Log messages from various sources are seamlessly processed and interpreted, offering security analysts a real-time understanding of potential threats and vulnerabilities.
Using LLMs models is a promising approach to improving cybersecurity.
Of course, there are also several challenges to using LLMs in conjunction with a SIEM. The first challenge is that LLMs can be computationally expensive to train and deploy. Another challenge is that Models can be biased, potentially leading to inaccurate results. However, I believe the potential benefits of using LLMs within SIEM outweigh these challenges. As LLMs continue to develop, I expect them to become even more powerful and effective tools for cybersecurity.
Now, you know! 😉